
In my last post, I talked about the overwhelming pace of AI models getting released… and how each one claims it’s better than the previous one. In this post, I will talk about how these models are actually measured, and how we can determine which model is “best” … depending on the use case.
My Holistic Three-Pronged Approach to Understanding Which Model is “Best”
The way I decide which model best meets my needs and measure its abilities is by looking at three main things:
- Officially produced company release notes often including company-conducted and reported benchmarks.
- Verification and testing of benchmarks by independent researchers, academic institutions, and respected unbiased third parties verification, and the AI community impression (Overall ratings, reaction, and feedback from the AI community).
- My general impression after testing the model with my own tests and data based on my use case.
The Company’s Role
First, each time a new model is released, it’s common practice that the company releasing it will accompany the release with a research paper, in which it talks about all the improvements, new features, progress, and updated benchmarks.
The company themselves run the benchmarks and display them with the release of the model.
Benchmarks are a series of tests and evaluations, all different, that test the various abilities of an LLM. The benchmarking tests themselves are created by third parties and are often static.
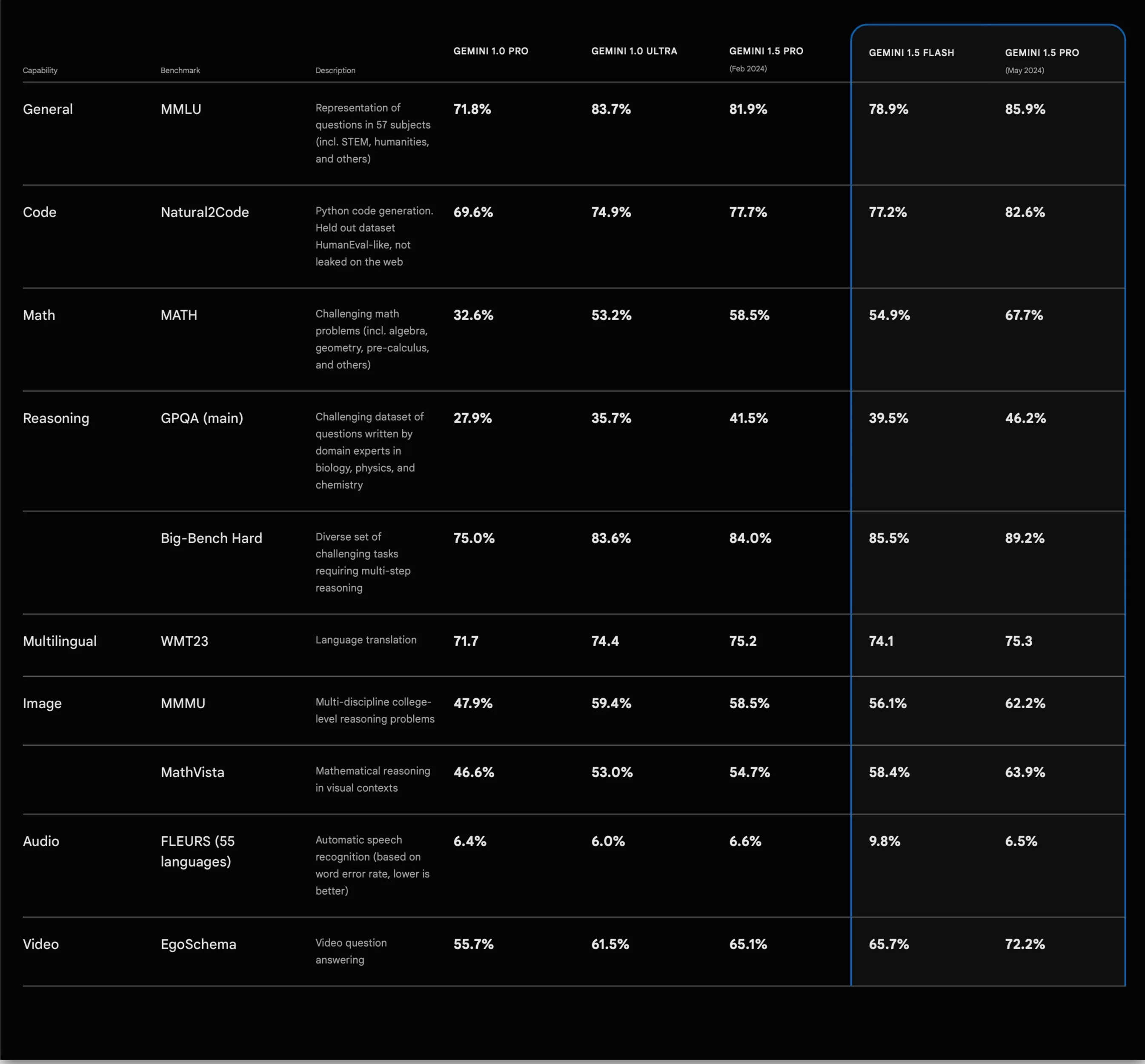
For example: With the recent update to Gemini 1.5 pro, Google emphasizes its new features (its 2 million token context-window), as well as a table showing how this updated model compares to its predecessors (with regards to benchmarks).
Third-Party Verification and Community Input
After the model is released, it is very common for various third parties to try and replicate the benchmark results provided by the company releasing it, to make sure it’s accurate and unbiased.
These third parties are often academic institutions, independent researchers, and more. Additionally, it’s common for the third parties testing the models standard benchmarks to conduct their own exams, benchmarks, and rubrics.
Where can we see these third party (unbiased) benchmarks?
I like to use benchmark aggregators like HELM for closed source frontier models, though it’s not updated so regularly. HELM (Holistic Evaluation of Language Models) from Stanford is an aggregator and leaderboard that compiles benchmarks.
When it comes to open-source models, I like OpenLLM from Hugging Face. There are more.
Then comes the community input:
The community consists of people actually using the models on their own, testing them on their own, conducting their own independent tests, or pitting models against each other.
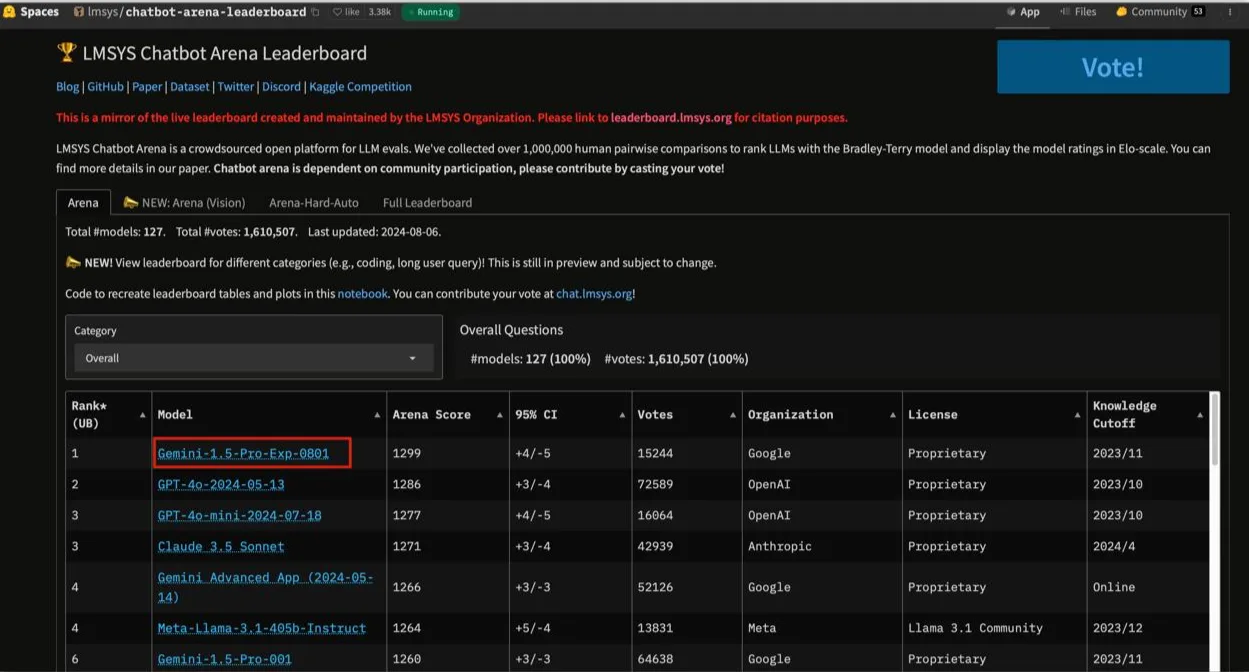
LMSys plays a great role in this. They not only provide tools and frameworks for testing, but they also created and hosted the “Chatbot Arena”, which is a head-to-head fight between certain models.
In Chatbot Arena, models are pitted against each other head-to-head, users are blindly given two chatbots, they are encouraged to provide any prompt, then the user votes blindly on which LLM answered best, only after voting does the user discover which LLM is which.
While the LMSys leaderboard can be viewed as more of a subjective opinion, I do believe that the power and opinion of the community is an important factor, and not in the sense of an online echo chamber such as Reddit, LinkedIn, X, or Facebook, but something that can be measured… As you see here, Google’s Gemini 1.5 pro is currently at the top of the leaderboard (and unlike Google’s own benchmarks, this shows the newest version from August 1):
My Own Testing and Opinion
I can’t overstate this enough: while my own feeling and opinion might be subjective, we all have different needs and use cases based on what we are trying to build or accomplish. I often will run my own tests, basic or advanced, with a model to see how it answers and evaluates my needs.
While I have my own set of questions and use cases for testing LLMs, I also draw inspiration from experts in the field. One such expert is Matthew Berman, an invaluable resource for all things AI. Matt has developed a comprehensive LLM testing rubric, which he regularly applies to new models in his YouTube channel. His insights on AI news, opinions, and frameworks are not only knowledgeable but also highly engaging. I’ve learned a great deal from following his work, and I often incorporate elements of his approach into my own testing process. I reccomend checking out his youtube: https://www.youtube.com/@matthew_berman
A Movie Analogy
Let’s use a movie to put this all into perspective… A new movie comes out, let’s say Wolverine and Deadpool (great movie btw). Before the movie even comes out, its studio will claim it’s the best movie ever (based on their own internally created benchmarks, but mainly from a sales and marketing ploy to promote the movie)… nevertheless, they say this before anyone has really seen the movie or have ticket sales.
Then comes the next layer: it comes down to official ratings of the reviewers (the third party), and the community response (ticket sales).
And ultimately, my own opinion after seeing the movie: did i like it, did it meet my expectations, was i wowed, was it good?
Each of these three elements can and should be used to decide what the current “best model” is, but I want to make a point here… there is no such thing as one “best” model. Each model, at the end of the day, has its pros and cons. Each model is usually better or worse at specific things than other models… and that brings us back to benchmarks…
Really Understanding Benchmarks
Benchmarks are a series of tests and evaluations, that each model goes through.
Each benchmark tests a different subject or abilities. Benchmarking subjects include math, writing, the ability to understand text, summarize text, coding abilities, reasoning abilities, and a bunch more.
Every benchmark like the MATH (testing math abilities) or HumanEval (testing the coding abilities) is comprised of a series of questions, kind of like a standardized test.
Once an LLM is run through a benchmarking test (comprised of a series of questions), an evaluation score is created based on their results.
Key Benchmarks to Watch
Since there are tons of benchmarks. I will highlight just a few of them (the ones I always look at):
1.MMLU (Massive Multitask Language Understanding)
MMLU tests knowledge across 57 subjects. A sample question might be:
What is the main function of the mitochondria in a cell?
A) Protein synthesis B) Energy production C) Cell division D) Waste removal
- HumanEval
This benchmark assesses code generation. An example task:
“Write a Python function that takes a list of integers and returns the sum of all even numbers in the list.”
The LLM would need to generate correct, functional code to solve this problem.
- GLUE/SuperGLUE
These benchmarks test natural language understanding. A sample question:
Text: The cat sat on the mat. Hypothesis: There is a cat on the mat.
Does the text entail the hypothesis? (Yes/No)
- HellaSwag
This benchmark evaluates common-sense reasoning through sentence completion. An example:
“The man grabbed a jug of milk from the refrigerator. He then…
A) poured it into a glass B) put on his shoes C) turned on the TV D) opened the window”
- MATH and GSM8K
The math benchmark consists of 12,500 problems sourced from high school math competitions and covers a range of mathematical sub-disciplines and difficulty levels, while the GSM8K is used to test LLMs on grade-school level math problems. An example question might be:
Problem:
A rectangle has a length that is twice its width. If the perimeter of the rectangle is 36 units, what are the dimensions of the rectangle?
It’s important to note that many benchmarks are synthetic and may not always accurately reflect real-world scenarios. While they provide valuable insights into model capabilities, they shouldn’t be the sole factor in determining a model’s effectiveness for specific applications.
After looking at benchmarking questions and the benchmarking leaderboards , it becomes clear that the newest model isnt always better at everything than its predecessor or even than its competition.
While one model could be better at writing and reasoning, another model could be better at math, yet worse than its predecessor at reasoning.
The Challenge of Benchmark Questions
But I’ll also point out that while every new model seems to improve on the benchmarks, the benchmarking questions are known and not changed very often. I have a feeling that in order to appear to surpass previous benchmarks some companies are training their models off of the benchmarking questions, which is kind of unfair.
This phenomenon, known as “benchmark overfitting,” occurs when models are trained to perform well on specific benchmark tests rather than improving general capabilities.
The Importance of Math in AI Development
Now I want to take some time to talk about LLMs and math a bit more… since this is a huge sticking point for the current generation of LLMs, but also where we are likely to see the most improvements in the near future.
Math is believed to be one of the most important stepping stones to reaching AGI as it is often crucial for reasoning, logic, planning, and self-learning.
Why is math so difficult?
Unlike other benchmarks and tests where multiple correct answers are possible—such as in reasoning, logic, or text creation—math requires a single, precise solution. This makes it particularly difficult for LLMs, which are designed to predict the next word or token based on patterns rather than arriving at an exact answer.
Despite these challenges, LLMs are improving. For example, just last week, Google’s Gemini 1.5 Pro made significant strides by outperforming others in a math olympiad. While progress in math benchmarks is slower than in other areas, it remains a critical focus for me, especially since many AI applications in business rely more on mathematical accuracy than on content generation.
Conclusion: Choosing the Right Model for Your Needs
Deciding which model is best isn’t always straightforward. Often, it comes down to personal preference. However, picking the right model is crucial for saving money and ensuring efficiency.
If your primary goal is to handle calculations or derive business insights, you’ll want a model that’s strong in math. But if you’re focused on writing or summarization, you’ll likely choose a model that excels in those areas based on relevant benchmarks. The key is to select the LLM that best suits your specific use case.
That said, be cautious about switching models too frequently. You might wonder, “We’ve been using Model X, but I just saw that Model Y is 50% better on Benchmark Z—should we switch?” Given how often new models are released, it can be tempting to jump to the latest and greatest. But if you’re considering a major switch—at the code and API level, not just a subscription—think twice. While it may seem easy to switch models (often just an API key), each model comes with its own nuances: different prompting methods, tokenization, and output formats. And that’s not even considering if you’ve fine-tuned your current model.
Sure, switching between models might be straightforward in theory, but in practice, it’s often inefficient, time-consuming, and costly. I wouldn’t recommend making a switch every time a new model with slightly better benchmarks comes out. Stick with your current model unless it no longer meets your specific needs.
So, take the time to understand the differences between models, how to interpret benchmarks, and how to choose the right model for your use case—not just the most popular one. I know it’s confusing and overwhelming with all the new releases, but it’s also an exciting time. This exciting progress underscores the importance of choosing the right model today, as each step forward in AI brings us closer to truly agentic LLMs and eventually AGI.